from majordome import MajordomePlot
from casadi import (inf, integrator, nlpsol, linspace, vertcat, MX, SX)11 DAE multiple shooting
Originally created by Joel Andersson in 2015
In this notebook we seek to solve the optimal control problem (OCP) given by
\[ \min\int_{0}^{10}x_0^2+x_1^2+u^2dt \]
subjected to
\[ \begin{aligned} \dot{x}_0 &= zx_0-x_1+u & \quad{}t\in[0,10]\\ \dot{x}_1 &= x_0 & \quad{}t\in[0,10]\\ 0 &= x_1^2+z-1 & \quad{}t\in[0,10] \end{aligned} \]
with boundary values
\[ \begin{aligned} x_0(t=0) &= 0\\ x_1(t=0) &= 1\\ x_0(t=10) &= 0\\ x_1(t=10) &= 0 \end{aligned} \]
and bounded control \(u\in[-0.75;1.00]\) over the whole interval, with \(z\) being an algebraic variable.
An alternate implementation and description of this problem is provided with Dymos package.
We start by importing all required tool explicitly.
The problem is build on SX symbolics defined as follows:
x0 = SX.sym("x0")
x1 = SX.sym("x1")
z = SX.sym("z")
u = SX.sym("u")The different problem equations can then be written as:
# Lagrange cost term (quadrature)
quad = x0**2 + x1**2 + u**2
# Differential equation
ode = vertcat(
z * x0 - x1 + u,
x0
)
# Algebraic equation
alg = x1**2 + z - 1Time integration parameters are then declared:
# Number of intervals.
nk = 50
# Final time [s].
tend = 10.0
# Time step [s].
tf = tend / nkTo provide x to integrator we need to have it as a state vector, which can be compiled by concatenating the states x0 and x1 using vertcat. Below we use the interface to Sundials IDAS to provide DAE time-stepping later in multiple shooting. The value of tf in the opts dictionary provide the integration time step.
dae = {"x": vertcat(x0, x1), "z": z, "p": u,
"ode": ode, "alg": alg, "quad": quad}
I = integrator("I", "idas", dae, 0.0, tf)To differentiate the variables from DAE to those of multiple shooting NLP, we will use w in what follows. Below we initialize arrays for variables, bounds, constraints, and the value of cost function. These will be used to build the NLP.
# List of variables
w = []
# Lower bounds on w
lbw = []
# Upper bounds on w
ubw = []
# Constraints
g = []
# Cost function
f = 0.0For multiple shooting we use MX symbolics. For enforcing initial state in NPL we create a first state Xk and enforce its lower and upper bounds (lbw and ubw) to match the values given in problem statement.
Xk = MX.sym("X0", 2)
w.append(Xk)
lbw.extend([0.0, 1.0])
ubw.extend([0.0, 1.0])The idea behind multiple shooting integration loop is quite simple:
we create a local control \(u_k\) to integrate over \(t_k\) to \(t_{k+1}\), which is a free variable in NLP problem, thus it must be added to
wand its bounds tolbwandubw,then we call the DAE integrator to retrieve (symbolically here) the state and lagrangian quadradure that is produced with control \(u_k\) and current problem state \(x_k\),
perform variable lifting, i.e. we store predicted state and create a new symbolic state which is now a free variable and must again be added to
wand its bounds tolbwandubw,finally we constrain the created state to match the previous prediction in
g, what is the shooting part of the integration.
for k in range(nk):
# Local control
Uk = MX.sym(f"U{k}")
w.append(Uk)
lbw.append(-0.75)
ubw.append( 1.00)
# Call integrator function
Ik = I(x0=Xk, p=Uk)
Xk = Ik["xf"]
f += Ik["qf"]
# "Lift" the variable
X_prev = Xk
# Create new symbolic state
Xk = MX.sym(f"X{k+1}", 2)
w.append(Xk)
lbw.extend([-inf, -inf])
ubw.extend([+inf, +inf])
# Constrain problem
g.append(X_prev - Xk)To solve the problem we allocate an NLP solver. Notice that the interface of nlpsol is quite similar to the one of integrator. Here we make use of Ipopt to perform optimization. Below we can inspect the interface of the function created by the wrapper.
nlp = {"x": vertcat(*w), "f": f, "g": vertcat(*g)}
# "ipopt.output_file": "ipopt.txt"
opts = {"ipopt.print_level": 3,
"ipopt.linear_solver": "mumps"}
solver = nlpsol("solver", "ipopt", nlp, opts)
solverFunction(solver:(x0[152],p[],lbx[152],ubx[152],lbg[100],ubg[100],lam_x0[152],lam_g0[100])->(x[152],f,g[100],lam_x[152],lam_g[100],lam_p[]) IpoptInterface)To solve the NLP we provide an initial guess, the bounds of free variables and the ones of constraints (lbg andubg`. Notice that you could provide constraint relaxation in some cases as allowed by specific problems.
sol = solver(x0=0.0, lbx=lbw, ubx=ubw, lbg=0.0, ubg=0.0)
******************************************************************************
This program contains Ipopt, a library for large-scale nonlinear optimization.
Ipopt is released as open source code under the Eclipse Public License (EPL).
For more information visit https://github.com/coin-or/Ipopt
******************************************************************************
Total number of variables............................: 150
variables with only lower bounds: 0
variables with lower and upper bounds: 50
variables with only upper bounds: 0
Total number of equality constraints.................: 100
Total number of inequality constraints...............: 0
inequality constraints with only lower bounds: 0
inequality constraints with lower and upper bounds: 0
inequality constraints with only upper bounds: 0
Number of Iterations....: 11
(scaled) (unscaled)
Objective...............: 2.8826157589618751e+00 2.8826157589618751e+00
Dual infeasibility......: 1.9331531178611032e-10 1.9331531178611032e-10
Constraint violation....: 2.0780707155054756e-09 2.0780707155054756e-09
Variable bound violation: 0.0000000000000000e+00 0.0000000000000000e+00
Complementarity.........: 5.3030799022244858e-09 5.3030799022244858e-09
Overall NLP error.......: 5.3030799022244858e-09 5.3030799022244858e-09
Number of objective function evaluations = 12
Number of objective gradient evaluations = 12
Number of equality constraint evaluations = 12
Number of inequality constraint evaluations = 0
Number of equality constraint Jacobian evaluations = 12
Number of inequality constraint Jacobian evaluations = 0
Number of Lagrangian Hessian evaluations = 11
Total seconds in IPOPT = 1.043
EXIT: Optimal Solution Found.
solver : t_proc (avg) t_wall (avg) n_eval
nlp_f | 48.00ms ( 4.00ms) 29.46ms ( 2.45ms) 12
nlp_g | 1.00ms ( 83.33us) 29.63ms ( 2.47ms) 12
nlp_grad_f | 306.00ms ( 11.77ms) 311.85ms ( 11.99ms) 26
nlp_hess_l | 468.00ms ( 42.55ms) 469.85ms ( 42.71ms) 11
nlp_jac_g | 197.00ms ( 15.15ms) 204.59ms ( 15.74ms) 13
total | 1.05 s ( 1.05 s) 1.06 s ( 1.06 s) 1Below you can inspect the keys in solution dictionary. We are looking for x here. Since the constraint violation in the report above is acceptable, we can skip the detailed inspection of g residuals. You can also check the value of cost f.
sol.keys()dict_keys(['f', 'g', 'lam_g', 'lam_p', 'lam_x', 'x'])Since when creating free variables vector w we started by initial states before entering the loop to add controls and following states, we have that starting on index 0 the variables correspond to \(x_0\), index 1 to \(x_1\), and index 2 to \(u\). Since there are three variables, we recover then every 3 elements using slicing syntax.
Note: by calling method full() we convert CasADi DM numerical array to plain Numpy. Since this will produce one dimension per element, it is usefull to call ravel() and get an one-dimensional array.
xs = sol["x"].full().ravel()
x0 = xs[0::3]
x1 = xs[1::3]
us = xs[2::3]Because we have an initial state, there are nk+1 states and nk control intervals. To proper represent them graphically we allocate corresponding time arrays.
tx = linspace(0.0, tend, nk + 1).full()
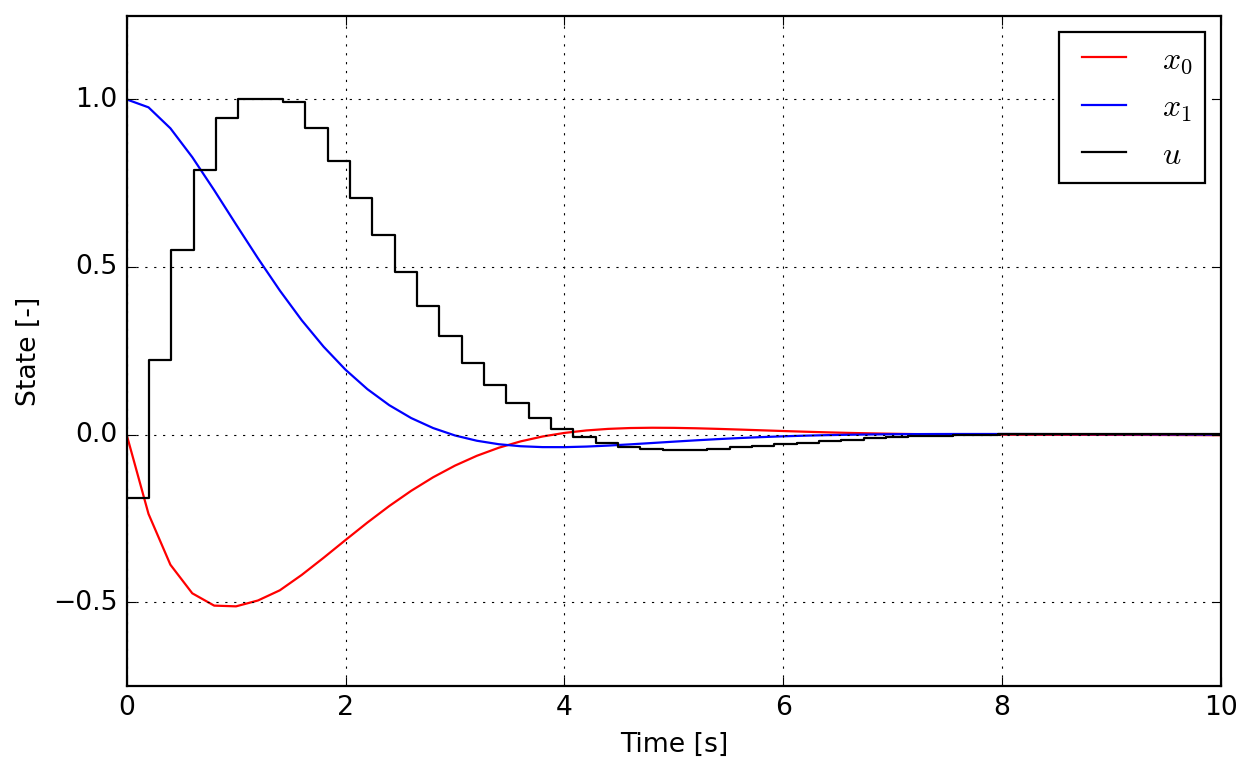
tu = linspace(0.0, tend, nk + 0).full()Finally the full solution can be visualized. Since controls are held constant over intervals, a step representation is more adapted for this variable.
@MajordomePlot.new(size=(8, 5), xlabel="Time [s]", ylabel="State [-]")
def plot_results(tx, tu, x0, x1, us, tend, plot=None):
_, ax = plot.subplots()
ax[0].plot(tx, x0, "r", label="$x_0$")
ax[0].plot(tx, x1, "b", label="$x_1$")
ax[0].step(tu, us, "k", label="$u$", where="post")
ax[0].set_xlim(0, tend)
ax[0].set_ylim(-0.75, 1.25)
ax[0].legend(loc="upper right", frameon=True)plot = plot_results(tx, tu, x0, x1, us, tend)